本文共 9302 字,大约阅读时间需要 31 分钟。
之前写过一个理论性的内容,这节使用线性回归的例子来看看如何优化一个机器学习模型,也就是机器学习中的偏差和方差问题。
视频讲解:彻底搞定机器学习算法理论与实战——机器学习的建议和系统设计
视频链接:
实验环境:win10 jupyter
1 读取数据并查看
import numpy as npfrom scipy.io import loadmatimport scipy.optimize as optimport pandas as pdimport matplotlib.pyplot as plt%matplotlib inlinedata = loadmat('ex5data1.mat') # 读取数据放入字典中data.keys() # 查看有哪些数据"""dict_keys(['__header__', '__version__', '__globals__', 'X', 'y', 'Xtest', 'ytest', 'Xval', 'yval'])""" 书写一个加载数据的函数
def load_data(): """ 获取数据,并进行预处理 d['X'] shape = (12, 1) """ d = loadmat('ex5data1.mat') # 使用内建函数将所有的数据进行压缩成一个行向量并返回 return map(np.ravel, [d['X'], d['y'], d['Xval'], d['yval'], d['Xtest'], d['ytest']]) 获取实验数据
X, y, Xval, yval, Xtest, ytest = load_data()
绘图查看训练数据
# 绘图查看数据plt.scatter(X, y)plt.xlabel('water_level')plt.ylabel('flow') 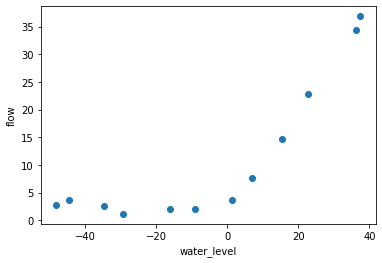
# 对数据进行预处理,即加入偏置特征X, Xval, Xtest = [np.insert(x.reshape(x.shape[0], 1), 0, np.ones(x.shape[0]), axis=1) for x in (X, Xval, Xtest)]
2 构建损失函数
常规损失
J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta)=\frac{1}{2 m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2} J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
正则化损失
J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + λ 2 m ∑ j = 1 n θ j 2 J(\theta)=\frac{1}{2 m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2}+\frac{\lambda}{2 m} \sum_{j=1}^{n} \theta_{j}^{2} J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2+2mλj=1∑nθj2
def cost(theta, X, y): """ 损失函数 args ---------- theta: 一个行向量(n,) 模型参数 X: 特征数据(m,n) m:为特征数据条数,n为包含偏置特征的总个数 y: 一个列向量(1,m) return: 常规损失 scalar """ m = X.shape[0] # 获取特征数据集个数 inner = X @ theta - y # 计算误差,返回(m,1) square_sum = inner.T @ inner # np.power(inser, 2).sum() cost = square_sum / (2 * m) # 计算各个数据损失值之和 return costdef regularized_cost(theta, X, y, l=1): """ 正则化损失函数 args ---------- theta: 一个行向量(n,) 模型参数 X: 特征数据(m,n) m:为特征数据条数,n为包含偏置特征的总个数 y: 一个列向量(1,m) l: lambda 正则化参数,默认为1 return: 正则化损失 scalar """ m = X.shape[0] # 获取特征数据集个数 # 计算正则化部分的损失 regularized_term = (l / (2 * m)) * np.power(theta[1:], 2).sum() return cost(theta, X, y) + regularized_term
查看损失值
theta = np.ones(X.shape[1]) # 初始化参数thetacost(theta, X, y), regularized_cost(theta, X, y) # 查看损失值,初始theta都为0,结果相同"""(303.9515255535976, 303.9931922202643)"""
3 构建梯度函数
常规梯度
∂ J ( θ ) ∂ θ j = 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) x ( j ) \frac{\partial J(\theta)}{\partial \theta_j} = \frac{1}{m}\sum_{i=1}^m\left(h_\theta(x_i) - y_i\right)x^{(j)} ∂θj∂J(θ)=m1i=1∑m(hθ(xi)−yi)x(j)
def gradient(theta, X, y): """梯度计算函数 args ---------- theta: 一个行向量(n,) 模型参数 X: 特征数据(m,n) m:为特征数据条数,n为包含偏置特征的总个数 y: 一个列向量(1,m) """ m = X.shape[0] # 获取特征数据集个数 # 计算各数据的梯度 inner = X.T @ (X @ theta - y) # (m,n).T @ (m, 1) -> (n, 1) # 返回参数的平均梯度 return inner / m
gradient(theta, X, y) # 无正则项初始化梯度"""array([-15.30301567, 598.16741084])"""
正则化梯度
∂ J ( θ ) ∂ θ 0 = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) for j = 0 ∂ J ( θ ) ∂ θ j = ( 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) ) + λ m θ j for j ≥ 1 \begin{aligned} \frac{\partial J(\theta)}{\partial \theta_{0}} &=\frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)} & \text { for } j=0 \\ \frac{\partial J(\theta)}{\partial \theta_{j}} &=\left(\frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)}\right)+\frac{\lambda}{m} \theta_{j} & \text { for } j \geq 1 \end{aligned} ∂θ0∂J(θ)∂θj∂J(θ)=m1i=1∑m(hθ(x(i))−y(i))xj(i)=(m1i=1∑m(hθ(x(i))−y(i))xj(i))+mλθj for j=0 for j≥1
def regularized_gradient(theta, X, y, l=1): """正则化梯度计算函数 args ---------- theta: 一个行向量(n,) 模型参数 X: 特征数据(m,n) m:为特征数据条数,n为包含偏置特征的总个数 y: 一个列向量(1,m) l:float 正则化系数,默认为1 """ # (9,) (1, 9) (1,) m = X.shape[0] # 获取特征数据集个数 regularized_term = theta.copy() # 复制一个与theta相同的变量 regularized_term[0] = 0 # 不需要正则化的变量设置为0 # 对需要正则化的theta进行正则化处理 regularized_term = (l / m) * regularized_term return gradient(theta, X, y) + regularized_term
regularized_gradient(theta, X, y) # 正则化梯度查看"""array([-15.30301567, 598.25074417])"""
4 模型拟合
def linear_regression_np(X, y, l=1): """线性回归 args: X: 特征矩阵, (m, n) 已插入偏置项1 y: 特征数据对应标签r, (m, ) l: lambda 正则化常数 return: 训练使用scipy训练的结果(theta值需要使用res.x获取) """ # 初始化参数 theta theta = np.ones(X.shape[1]) # 训练 res = opt.minimize(fun=regularized_cost, x0=theta, args=(X, y, l), method='TNC', jac=regularized_gradient, options={ 'disp': True}) return res # 计算获取拟合直线参数thetafinal_theta = linear_regression_np(X, y, l=0).get('x')final_theta"""array([13.08790348, 0.36777923])""" b = final_theta[0] # 截距interceptm = final_theta[1] # 斜率slope# 绘制拟合图形plt.scatter(X[:,1], y, label="Training data", c='r')plt.plot(X[:, 1], X[:, 1]*m + b, label="Prediction")plt.legend()
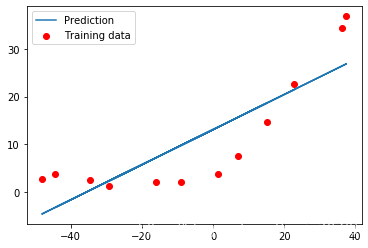
5 绘制学习曲线
在没有正则项以及特征映射情况下的学习曲线
注意:
1.使用训练集的子集来拟合应模型
2.在计算训练代价和交叉验证代价时,没有用正则化
3.使用相同的训练集子集来计算训练代价
# 创建训练损失集损失和交叉集损失training_cost, cv_cost = [], []
m = X.shape[0]# 数据逐渐增多的方法for i in range(1, m + 1): res = linear_regression_np(X[:i, :], y[:i], l=0) tc = regularized_cost(res.x, X[:i, :], y[:i], l=0) # 使用训练集得到的参数计算交叉验证集的损失 cv = regularized_cost(res.x, Xval, yval, l=0) # 记录每次计算得到的损失值 training_cost.append(tc) cv_cost.append(cv)
# 绘制学习曲线plt.plot(np.arange(1, m+1), training_cost, label='training cost')plt.plot(np.arange(1, m+1), cv_cost, label='cv cost')plt.xlabel('train size')plt.ylabel('cost')plt.title('Learning curves')plt.legend() 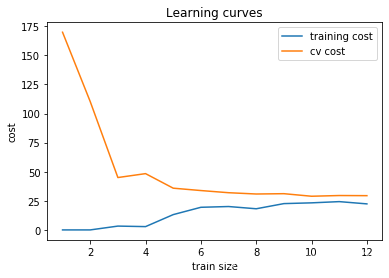
结果分析
从学习曲线图可以看出,随着数据的增多训练集误差和测试机误差相差不大,无论训练集有多么大误差都不会有太大改观。从损失值可看出,这个模型拟合不太好, 欠拟合了。
6 创建多项式特征
def prepare_poly_data(*args, power): """ 多项式特征构建 args: 多个特征数据 """ def prepare(x): # 扩展特征 df = poly_features(x, power=power) # 标准化数据,并转为numpy类型 ndarr = np.array(normalize_feature(df)) # 插入偏置项 ndarr = np.insert(ndarr,0, 1, axis=1) return ndarr return [prepare(x) for x in args]
def poly_features(x, power, as_ndarray=False): """扩展特征""" # 构建扩充数据的字典,并插入偏置项1 data = { 'f{}'.format(i): np.power(x, i) for i in range(1, power + 1)} # 创建dataframe数据 df = pd.DataFrame(data) return np.matrix(df) if as_ndarray else df def normalize_feature(df): """标准化数据 """ return df.apply(lambda column: (column - column.mean()) / column.std())
X, y, Xval, yval, Xtest, ytest = load_data() # 再次读取数据
poly_features(X, power=3) # 扩充数据特征
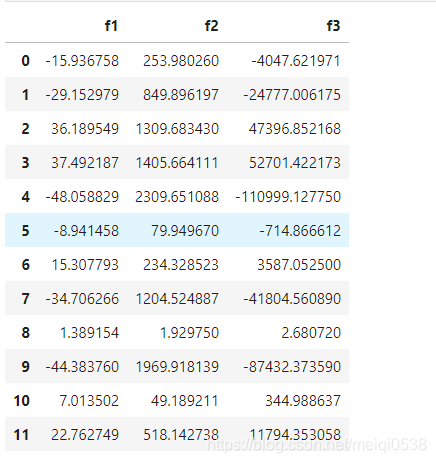
7 准备多项式回归数据
- 扩展特征到 8阶,或者你需要的阶数
- 使用 归一化 来合并 x n x^n xn
- 需要添加偏置项
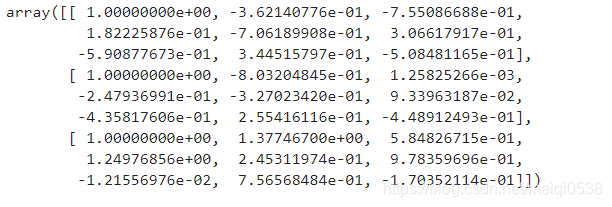
X_poly, Xval_poly, Xtest_poly = prepare_poly_data(X, Xval, Xtest, power=8) # 构建8阶的数据X_poly[:3, :] # 查看前3行数据
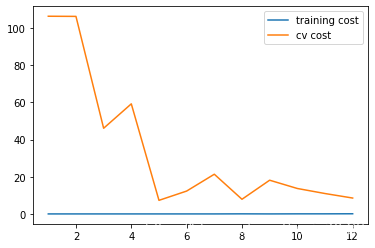
8 画出学习曲线
首先绘制无正则项的学习曲线,所以 λ = 0 \lambda=0 λ=0
def plot_learning_curve(X, y, Xval, yval, l=0): training_cost, cv_cost = [], [] m = X.shape[0] for i in range(1, m + 1): # 开始训练 res = linear_regression_np(X[:i, :], y[:i], l=l) # 根据训练得到参数计算在训练集、交叉验证集中的损失 tc = cost(res.x, X[:i, :], y[:i]) cv = cost(res.x, Xval, yval) training_cost.append(tc) cv_cost.append(cv) # 绘制学习曲线 plt.plot(np.arange(1, m + 1), training_cost, label='training cost') plt.plot(np.arange(1, m + 1), cv_cost, label='cv cost') plt.legend()
plot_learning_curve(X_poly, y, Xval_poly, yval, l=0) # 绘制学习曲线
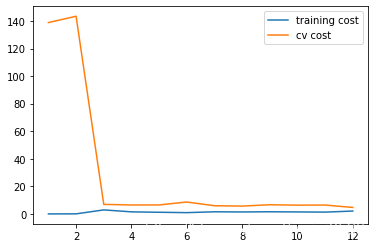
9 通过正则项优化模型
参数 λ = 1 \lambda=1 λ=1
plot_learning_curve(X_poly, y, Xval_poly, yval, l=1) # 绘制学习曲线
参数 λ = 100 \lambda=100 λ=100
plot_learning_curve(X_poly, y, Xval_poly, yval, l=100)
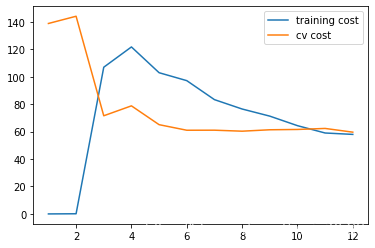
10 寻找最佳 λ \lambda λ
l_candidate = [0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10] # 通常设置的lambda的值training_cost, cv_cost = [], []
# 根据不同lambda查看训练集损失和交叉集损失for l in l_candidate: # 不同lambda的线性模型 res = linear_regression_np(X_poly, y, l) # 根据训练的模型参数计算损失值 tc = cost(res.x, X_poly, y) cv = cost(res.x, Xval_poly, yval) training_cost.append(tc) cv_cost.append(cv)
绘制不同的lambda情况下训练集和交叉验证集的损失情况
plt.plot(l_candidate, training_cost, label='training')plt.plot(l_candidate, cv_cost, label='cross validation')plt.legend()plt.xlabel(r'$\lambda$') # 使用latax,在绘图时显示lambda符号plt.ylabel('cost')plt.title("cost vs lambda") 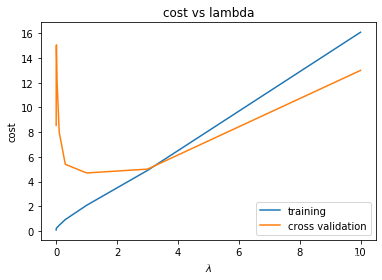
-
随着 λ \lambda λ值的增加训练集的损失值不断增大,模型朝着欠拟合的方向变化;
-
交叉验证机的损失值经历了先增大后减小再增大的过程。(测试集数据量比较小,导致先增大后减小)
-
λ \lambda λ选择在0-2之间,在交叉验证损失最小值时 λ \lambda λ的附近
# 获取交叉损失中,损失值最小的lambda值l_candidate[np.argmin(cv_cost)] # 在交叉验证集中,lambda=1时,损失值最小"""1"""
进一步寻找最优 λ \lambda λ 在测试集中查看。
# 使用测试数据计算损失for l in l_candidate: theta = linear_regression_np(X_poly, y, l).x print('test cost(l={}) = {}'.format(l, cost(theta, Xtest_poly, ytest)))"""test cost(l=0) = 10.804375286491785test cost(l=0.001) = 10.911365745177878test cost(l=0.003) = 11.265060784108712test cost(l=0.01) = 10.879143763702967test cost(l=0.03) = 10.022378551698187test cost(l=0.1) = 8.631776100446476test cost(l=0.3) = 7.3365081011786275test cost(l=1) = 7.466282452677015test cost(l=3) = 11.643940740451052test cost(l=10) = 27.715080273166386""" 结果分析: 在测试集中,可以看出当正则项 λ = 0.3 \lambda=0.3 λ=0.3的时候,损失值最小,那么调参后, λ = 0.3 \lambda = 0.3 λ=0.3 是最优选择,这个时候测试代价最小
总结
学会看懂学习曲线以及曲线走势所表达的意义对模型优化有很大的意义。
程序源码可在订阅号"AIAS编程有道"中回复“机器学习”即可获取。
转载地址:http://dmlxf.baihongyu.com/